Five Things | Scale Isn’t Enough
Why progress now depends on data realism, coordination, and feedback loops



Each week, we share a small collection of ideas, conversations, and artifacts that shaped our internal thinking. Inspired by experiments like USV’s Librarian, this series is powered by an AI assistant that helps synthesize recurring themes from our discussions, alongside our own reflections.
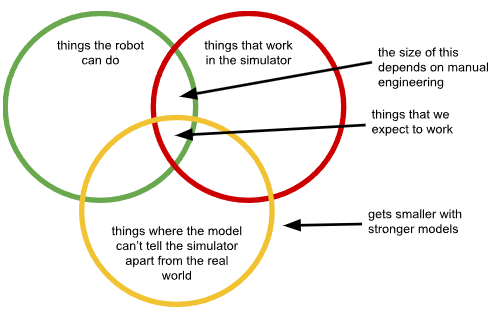
Messy, real-world data is beating clever shortcuts in robotics. In Sporks of AGI, Sergey Levine explains why vision-language-action models hit a wall when trained on surrogate data like simulations, human videos, or proxy devices. As models get stronger, they become better at spotting these mismatches, shrinking the set of skills that transfer to reality and forcing researchers to hide information or weaken the model. Our take is that this is the Bitter Lesson showing up again: any human-engineered shortcut meant to avoid reality eventually becomes the bottleneck, and real-world interaction data is the only path to scalable physical intelligence.
Execution speed is increasingly a coordination problem, not a tooling one. Dave Clark, former CEO of Amazon Worldwide Consumer, built a custom CRM for his company over a weekend after realizing off-the-shelf tools didn’t match how they actually sell. Standard CRMs forced unnecessary fields, missed the ones that mattered, and imposed a pipeline divorced from reality, creating more friction than leverage. Our take is that as software becomes cheaper to build and customize, the biggest gains will come from eliminating coordination overhead, not adopting more feature-rich tools.
Reasoning models work because they debate, not because they think longer. A new paper from DeepMind shows that models like o-series, DeepSeek-R1, and QwQ outperform not simply by generating longer chains of thought, but through internal debate and questioning, what the authors describe as “societies of thought.” Using interpretability tools, they find that a meaningful share of accuracy gains comes from these structured disagreements rather than raw compute or token count. We’ve long held the view that future gains in AI will come from architectures that make disagreement and verification first-class primitives.
2026 looks like the year AI leaves the text box. Physical and multimodal AI has been directionally obvious for years, but until recently it was impractical. What’s changed is that three constraints are easing at once: multimodal models are finally good enough, inference cost and latency are coming down fast, and the physical world is becoming legible through cameras, microphones, sensors, devices, and robots. Our view is that AI is moving from prompts to environments, showing up in workflows that are continuous, embodied, and real-time, and that text-only interfaces will soon feel as constrained as desktop-only software did after mobile.
Alignment is improving because it’s finally measurable. Over the course of 2025, models across Anthropic, Google DeepMind, and OpenAI have shown declining rates of misaligned behavior under automated auditing. Tools like Petri work by adversarially probing models in realistic scenarios and scoring failures with a separate judge model, giving researchers a concrete signal to optimize against. Our take is that once misalignment becomes observable, it becomes tractable.
We’ll share another edition next week.