One Framework to Run Them All
Agents, world models, robotics, and the end of ad-hoc systems



Each week, we share a small collection of ideas, conversations, and artifacts that shaped our internal thinking. Inspired by experiments like USV’s Librarian, this series is powered by an AI assistant that helps synthesize recurring themes from our discussions, alongside our own reflections.
DeepMind shows that an LLM’s “belief representations” can swing dramatically across a single conversation. In edge-case dialogues (consciousness, delusions, role-play-heavy contexts), internal representations of factuality can flip as the model shifts roles, while clearly fictional “sci-fi” framing stabilizes them. This makes interpretability less construct-valid. Our take: alignment is increasingly a stateful, conversational property, which means we’ll need coordination primitives (audit trails, provenance, shared oversight), not just one-shot “steering,” to manage safety.
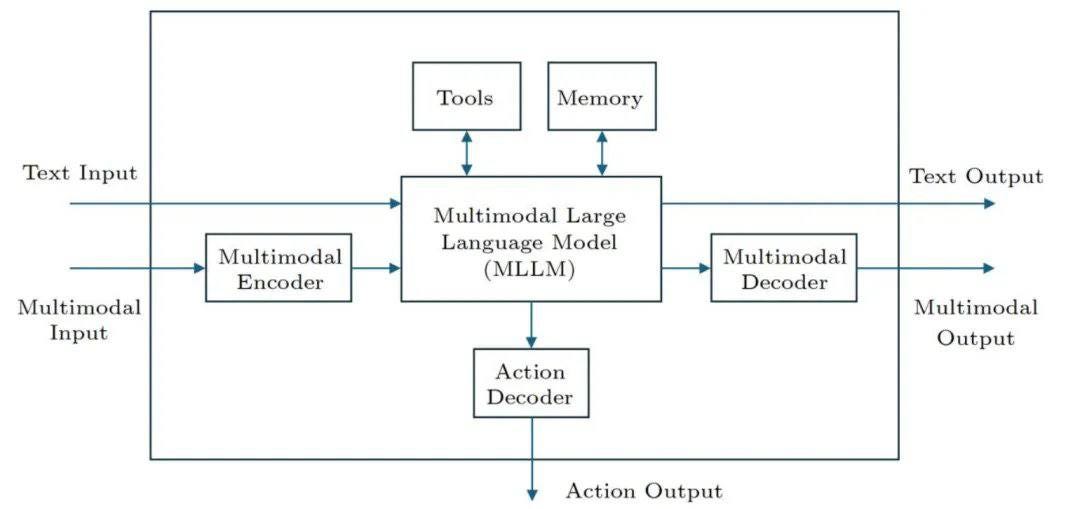
What if a single framework could unify every AI agent? A new paper from ByteDance proposes a general architecture that spans both software agents and physical robots: task-oriented systems that use LLMs for reasoning, reinforcement learning for behavior, and tools plus long-term memory for execution. Our take: progress will come less from inventing new “agent types” and more from standardizing this stack, making agents easier to compose, reason about, and eventually govern at scale.
World models are the second pre-training paradigm. Models are now learning to predict how the physical world evolves under action. Video generators are the shallow end of this shift; the deep end is learnable physics simulators that reason in vision-first, action-conditioned space. We’ve written before about why this matters for robotics and Physical AI. Our take: 2026 is the year world models stop being a curiosity and start becoming the substrate for robotics, multimodal agents, and real-world autonomy, with language receding from foundation to scaffold.

Physical commonsense is the missing substrate in robotics. Humans rely on reflexive, closed-loop corrections (nudges, regrips, recoveries) that feel automatic. This kind of intelligence isn’t linguistic; it lives in the sensorimotor loop for robotics and only emerges when data preserves real interaction, not slow, stilted teleoperation. We think the next step-change in robotics comes from better priors learned from reflex-level human behavior, not better planners, and the teams that capture this will own generalization.

Hyperliquid launches outcome trading, a general-purpose primitive for prediction markets and dated, bounded options. This expands HyperCore beyond perps into a broader derivatives substrate. Our take is that this is a real step toward “everything exchange” behavior, with the open question being whether Hyperliquid can keep adding primitives without sacrificing the simplicity and reliability that made it win in the first place.

We’ll share another edition next week.