Power In, Heat Out: An AI Data Center Primer
Why power, not chips, is the real bottleneck. And why AI is both the strain on the buildout and the tool finishing it.

Red dirt in Johor
Last week a couple of days after my panel at SuperAI in Singapore on “Compute, Chips and the Cost of Intelligence“, I stood on a cleared lot in Johor, Malaysia, watching a future AI data center get staked out. Everyone on that panel was talking about GPUs. But what decides whether that lot in Johor becomes a working cluster is not just chips. It is whether you can get a gigawatt of power to the dirt, cool it, and find people who know how to run it. That gap is what this post is about.
It is a companion to our map at canonical.cc/labs/data-centers, which tracks 31 players across 7 layers. It sits next to our Semiconductor Stack and Decentralized AI maps. Body, brain, nervous system of the buildout.
The strange loop
Our silicon primer was predicated on this fact:
the technology breaking the chip industry is the same technology most likely to fix it.
AI demand is breaking the grid. A single campus now draws a gigawatt, a small city’s worth of power for one building. And AI is turning out to be the best tool we have for designing those power systems, tuning the cooling, and squeezing more compute from concrete we already poured.
A building, on a napkin
A data center is a building full of computers. Power comes in, heat comes out, compute happens in between. That is the whole thing. We went from server rooms, to the cloud, to the AI explosion, and the physics never changed. Only the scale did.
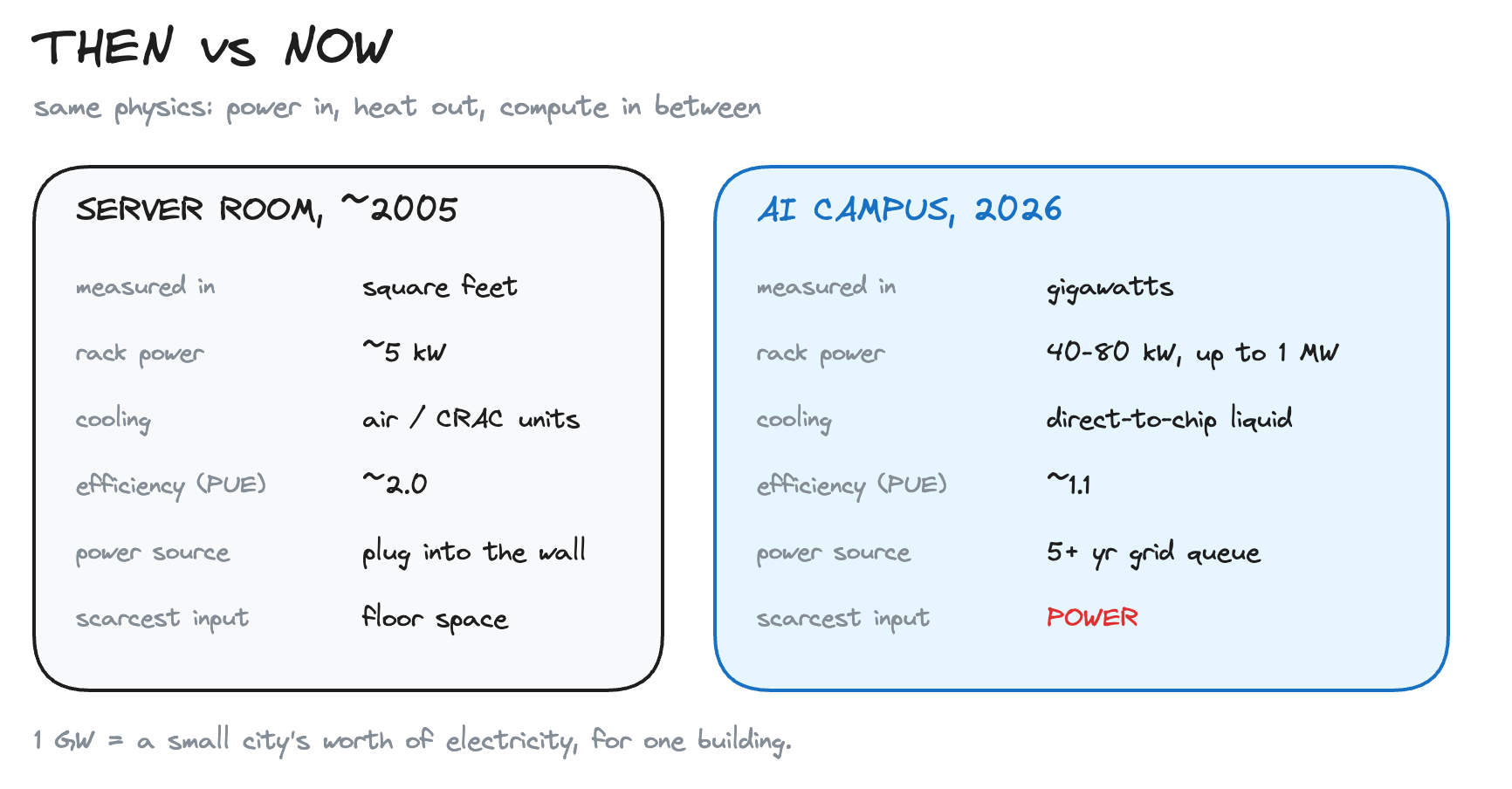
The number everyone quotes is PUE, Power Usage Effectiveness: total power divided by the power that reaches the chips. A PUE of 1.2 means you burn 0.2 watts on cooling for every watt of compute. The old server room ran near 2.0. Liquid-cooled AI halls are pushing toward 1.1. At gigawatt scale, that gap is a power plant’s worth of waste.
Now stack it up. From the rental product at the top to the grid at the bottom, every layer is its own market.
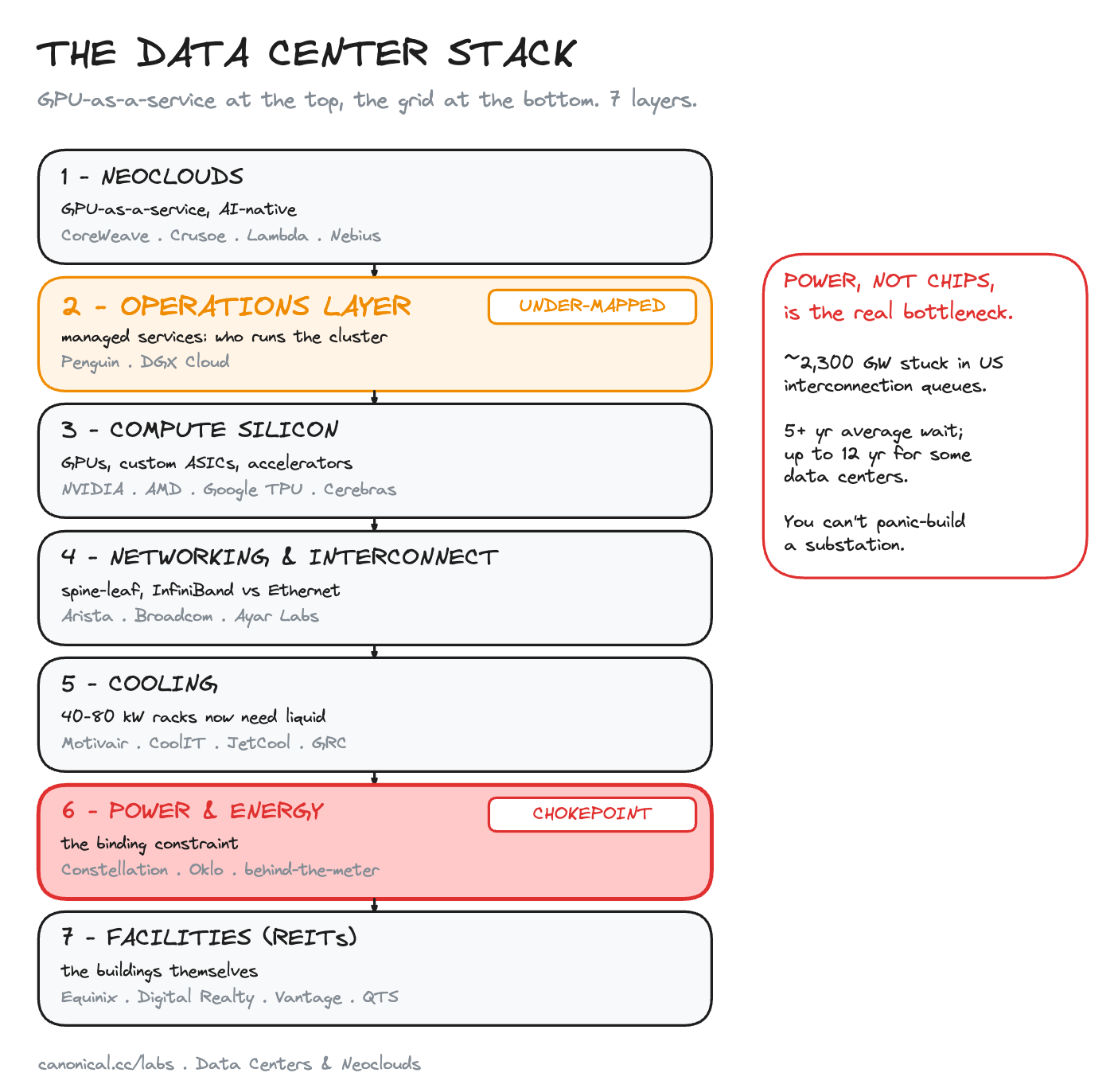
1. Neoclouds. The product most AI companies buy: GPUs by the hour, no enterprise baggage. CoreWeave, Crusoe, Lambda, Nebius. CoreWeave proved the category reaches public scale. It also exposed the category’s central risk, below.
2. Operations. Who runs the cluster once it is powered on. The quietest layer on the map, and we think the most mispriced. More below.
3. Compute silicon. The GPUs and accelerators. NVIDIA, AMD, Google TPU, Cerebras. Everyone fights here. We cover it in the silicon map, so we will skip it.
4. Networking. Past 100,000 GPUs, the bottleneck stops being compute and becomes moving data between chips. Arista, Broadcom, optical-I/O upstarts like Ayar Labs.
5. Cooling. Old racks drew 5 to 20 kilowatts; air handled it. AI racks draw 40 to 80 today, and NVIDIA is targeting a megawatt per rack on Rubin Ultra. Air cannot touch that. Liquid goes straight to the chip. Motivair, CoolIT, JetCool.
6. Power. The binding constraint. Constellation restarting Three Mile Island, Oklo and small reactors, plus a fast-growing layer of on-site generation and batteries that smooth a training run’s spiky draw.
7. Facilities. The buildings and land, mostly held in REITs. Equinix, Digital Realty, Vantage, QTS.
So where does it break?
Which layer can actually stop the buildout?
In silicon, the answer was two companies: ASML and TSMC. Here it is not a company. It is power.
About 2,300 gigawatts of generation sit stuck in US interconnection queues, more than the country’s entire installed capacity.
The average project waits five years to connect. Some data centers are quoted twelve.
US data-center demand is headed for roughly 76 gigawatts in 2026, up from 50 in 2024.
In Texas, large-load requests to one utility jumped sevenfold in a year.
Bessemer counts 190 gigawatts of hyperscale capacity already announced against 5-7 year queues.
“We need more compute” is something we are all hinding behind. The world is not just short on chips this quarter. It is short on energized, cooled, staffed megawatts. You can panic-order GPUs. You cannot panic-build a substation, and you cannot panic-train the people who run the room.
Where AI causes the squeeze
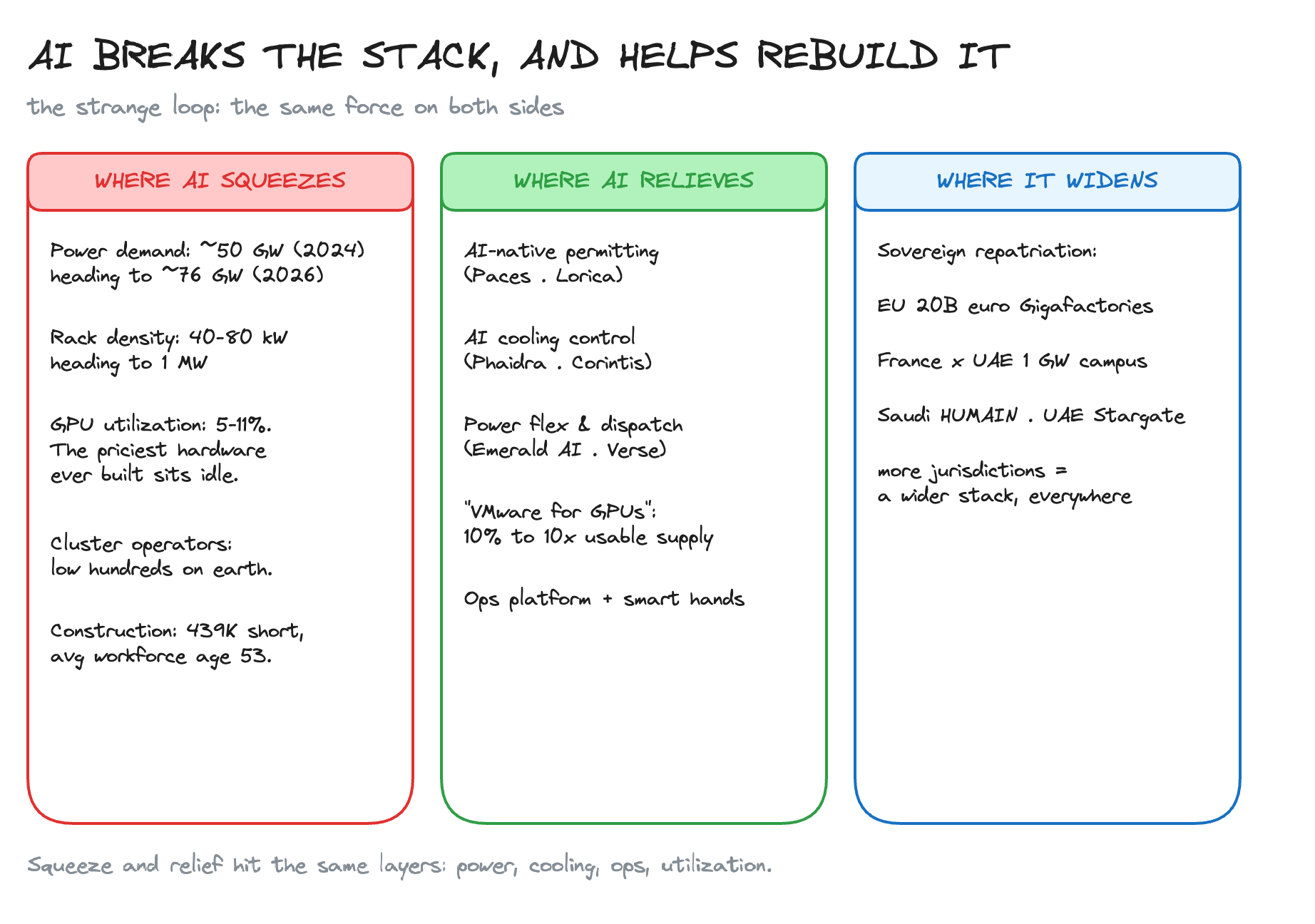
Power takes the direct hit. Cooling takes the next one, as rack density climbs an order of magnitude and liquid goes from exotic to mandatory.
Then the strangest one: utilization. The most expensive hardware ever built mostly sits idle. xAI’s fleet reportedly runs near 11%. Hyperscalers run 5-10%. We spent 25 years learning to share CPUs with VMs, containers, and schedulers. Almost none of that exists for GPUs yet. So we scream about a shortage while most of our GPUs sit parked.
Under all of it, people. Maybe a few hundred humans on earth have run a multi-thousand-GPU cluster end to end. The demand is the entire buildout. Construction is no better: the trade is short hundreds of thousands of workers, the average data-center worker is 53, and most operators cannot fill ops roles. The pain lands where the talent is thinnest. Not a coincidence.
Where AI relieves it
The same intelligence stressing the grid is being pointed back at the stack. AI permitting software is compressing the slowest, most bureaucratic step in the build (Paces, Lorica). AI runs cooling and power inside live halls (Phaidra, Corintis). A new layer makes GPU work power-flexible, so a cluster leans into cheap power and backs off when the grid is tight (Emerald AI, Verse). Construction is getting robots (Gecko Robotics, DroneDeploy).
The highest-leverage bet sounds the dullest. Build “VMware for GPUs,” real multi-tenancy and scheduling, and a 10 percent utilization problem becomes a 10x supply unlock. That is more new compute than most fabs add in years, and it ships in software.
Will any of this beat the power constraint this decade? No. Electrons obey physics and permitting, not roadmaps. But the software-shaped layers (permitting, orchestration, utilization, operations) compound in quarters, not half-decades. That is where venture lives.
Sovereign AI: the repatriation trend worth watching
For two decades the logic was centralize: ship compute to whoever had the cheapest power. That is reversing, fast. Countries now treat AI compute as critical infrastructure, like a grid or a port, and they want it on home soil under home law. Some call it geopatriation. I call it the most important capital-flows story in infrastructure right now.
The EU has put 20 billion euros behind AI Gigafactories. France is building a 1-gigawatt campus with the UAE worth tens of billions, while backing Mistral as its champion. Saudi Arabia stood up HUMAIN under its sovereign fund to build the whole stack. The UAE is breaking ground on a multi-gigawatt cluster in Abu Dhabi. Japan and Singapore are moving the same way. We see it at seed stage too, with founders pitching energy-first inference backbones built for Europe.
Repatriation does not shrink the stack, it widens it. Every sovereign build needs its own power, its own cooling, and its own operators, in a country that has never run a frontier cluster. The talent gap that is acute in Virginia becomes a wall in Riyadh or Johor. Many national buildouts means the power and operations layers get demanded everywhere at once. That is the picks-and-shovels case, multiplied by the flags on the map.
Why this could fail
I would be selling you a dream if I skipped the bear case. It is real and specific.
The sharpest risk is financial. Neoclouds buy GPUs with GPU-backed debt. If utilization or pricing softens, the collateral can depreciate faster than the loans amortize, and one demand wobble cascades through the most leveraged layer. CoreWeave’s bull case and bear case are the same fact. Add regulatory backlash (moratoriums, water fights, grid-reliability fights are already spreading) and the chance that hyperscalers re-bundle and fix the allocation problems that created the neocloud layer in the first place. And the deepest question stays open: does inference get effectively free as efficiency compounds, or does demand outrun supply forever, keeping power the permanent constraint? The thesis hinges on which way that breaks.
Our read: the bull case is already priced into the obvious layers, silicon and the public neoclouds. We would rather underwrite where the centralized option is structurally weak and demand is non-negotiable. Power. Liquid cooling. And the operators who turn a half-billion-dollar building full of idle silicon into a working cluster.
The exciting part
Today, standing up AI compute takes a hyperscaler’s balance sheet and a team that barely exists. Productize the operations and power layers and that capability gets unbundled: handed to the sovereign, the enterprise, the neocloud in a country you would not have guessed. Standing up a cluster starts to look less like building a refinery and more like provisioning a service.
Somewhere on that lot in Johor, rebar is going in for a building that will think. Whether it ever does comes down to the least glamorous layers on the map: the wire coming in, the heat going out, and the few people who can keep it alive at 3am. That is the layer we are building toward.
The flashy layers (silicon, the public neoclouds) are mostly priced. The middle (power, cooling, operations) is where we think the next infrastructure companies get built, and where AI is the relief, not the strain. We track all of it, layer by layer, with sources and caveats, on the full map.
Explore the map: Data Centers & Neoclouds at Canonical Labs →
Educational, not investment advice. Figures are point-in-time as of June 2026.